
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- xml
- 카카오APi
- XML Core
- HTTP
- 데이터규정
- 스프링프레임워크
- 반응형웹
- java annotation
- Ajax
- java컴파일
- 자바
- 세션
- Database
- 웹프로그래밍
- 프로그래밍용어
- Session
- Java
- Request/Response Header
- 공문서작성규정
- xml mapping
- XML DOM
- Multipart
- 데이터포맷
- 데이터문서포맷
- 데이터베이스
- JSTL
- Servlet
- 자바스크립트
- JSP
- JavaScript
- Today
- Total
KyungHwan's etc.
카카오톡 대화 wordcloud 구현 본문
1. 카카오톡 대화 내보내기
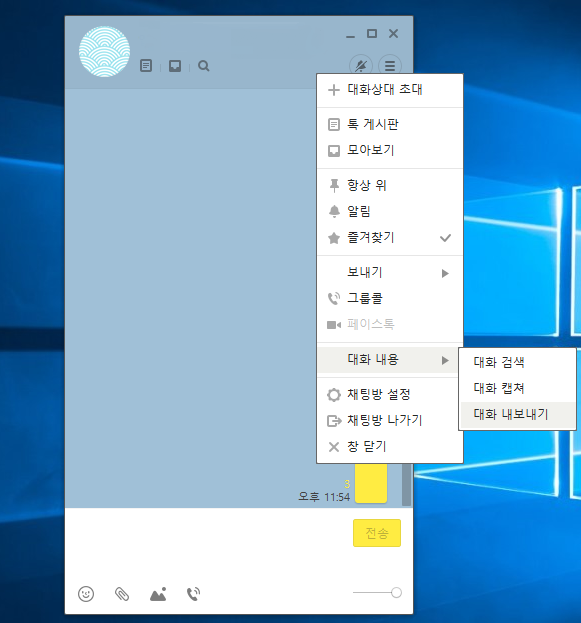
카카오톡 대화방의 메뉴 중에 대화내용 - 대화 내보내기를 선택하면 대화내용 전체를 텍스트파일로 저장할 수 있습니다.
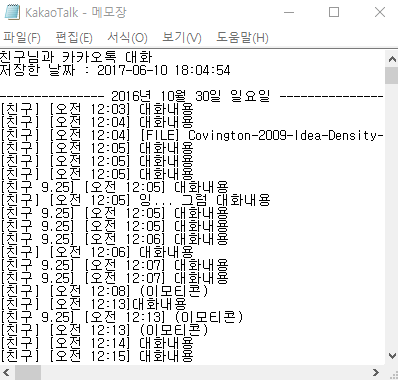
대화내보내기 기능은 모바일과 PC로 대화를 내보냈을 때 저장되는 형태가 다릅니다. 대화 내용을 분석하기 위해 보낸 사람의 이름과 날짜를 제거하기에는 PC가 수월하지만, 모바일이 정보의 양이 훨씬 많기때문에 이번 포스팅에서는 모바일 버전으로 사용하겠습니다.
2. 데이터 읽기
readLines는 txt파일을 불러올 때 사용하는 함수입니다.
txt가 한글일 경우 R에서 인식하지 못하는 경우가 많기 때문에 'iconv(아이콘브이)' 를 사용해서 인코딩해주었습니다. 인코딩 형식은 'UTF8'이 일반적입니다.
3. 필요한 정보만 남기기
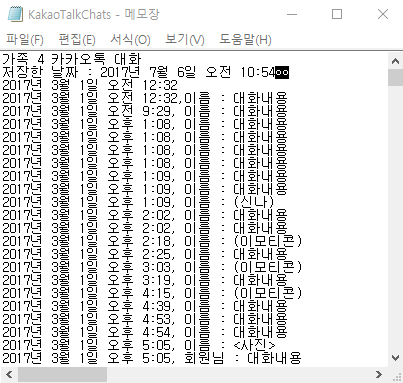
대화 내용을 분석함에 있어 날짜와 보낸 사람의 이름은 중요하지 않기 때문에 'gsub' 함수와 정규표현식으로 지워줍니다.
1) 날짜와 이름 지우기
(2017년).+(:) : 2017년 부터 : 사이에 글자가 포함되어있는 형식을 찾아 지워줍니다.
'.'은 모든 글자를 의미하며 한글, 영어, 숫자 모두를 포함합니다. '+'는 {1, }, '하나
이상'을 뜻합니다. 즉, '(2017년) 하나 이상의 모든 글자 (:)' 로 이루어진 텍스트를
찾아 지워줍니다.
[], () : 텍스트를 대괄호( [텍스트] )로 묶어주면 대괄호 안에 묶인 글자 중 하나라도 매칭되는 것을 찾아
줍니다. 소괄호( (텍스트) )는 소괄호 안에 묶인 글자 모두가 매칭되는 것을 찾아줍니다.
2) 자음/모음 의성어 지우기
ㅋㅋ과 ㅠㅠ같은 자음/모음 의성어를 지워줬습니다.
[ㄱ-ㅎ] : '자음 ㄱ(기역)부터 ㅎ(히읗)까지 전부' 를 의미합니다.
(ㅜ|ㅠ)+ : (ㅜ 또는 ㅠ)를 의미하며, +는 '하나 이상'을 뜻합니다.
3) 이모티콘 지우기
이모티콘을 지워줬습니다.
\\( : 괄호 ( 앞의 역슬래쉬는 '문자 그대로의'라는 뜻입니다. R에서 괄호는 그 자체만으로 의미를 갖기 때문에 문자 그대로의 괄호를 지우고싶다면 반드시 역슬래쉬를 괄호 앞에 위치시켜야합니다.
4) 초대 및 저장 날짜 지우기
5) 특수문자 지우기
불필요한 특수문자를 제거합니다. 지우고 싶은 특수문자를 모두 입력하면 됩니다.
6) 정리하기
na.omit으로 NA값을 제거합니다.
gsub을 이용해 ''로 대체했던 텍스트들을 dplyr패키지의 filter함수로 제거합니다.
7) 참고 : PC버전
pc버전에서 gsub을 이용해 불필요한 내용을 지우는 정규표현식을 첨부합니다.
gsub("\\[.+\\]", "", kko) : 괄호부터 괄호까지의 모든 텍스트를 지웁니다. '.' 은 모든 글자를 의미
하며, +는 하나 이상을 의미합니다. 즉, '[하나 이상의 모든 글자]'를
''으로 변환합니다.
gsub('\\-.+\\-','',kko) : --- 글자 --- 형식의 텍스트를 지웁니다.
4. 형태소 분석 및 TermDocumentMetricx 만들기
1) 형태소 분석 (extractNoun/ SimplePos09/ str_match)
형태소 분석 방식은 데이터에따라 더 효과적인 방법을 채택하여 사용합니다. 제가 저장한 데이터는 두 형태소 분석을 실행해봤을 때 명사, 형용사, 동사를 모두 추출하는 두번째 방식이 더 효과적으로 대화를 분석해주었습니다.
2) 말뭉치 만들기 (VCorpus)
단어가 몇번 쓰였는지 카운트해 나타내는 TermDocumentMetrix를 작성하기 위해 데이터의 텍스트를 단어의 말뭉치로 분리해주는 Vcorpus(VectorSource) 함수를 사용합니다.
3) TermDocumentMetrix 만들기 (TermDocumentMetrix)
앞서 VCorpus로 분리한 말뭉치를 바탕으로 TermDocumentMetrix를 작성합니다.
tokenize : 형태소 분석을 의미하며, 앞서 만들었던 형태소 분석 방식을 입력합니다.
removePunctuation : 마침표를 제거합니다.
removeNumbers : 숫자를 제거합니다.
stopwords : 문자 제거를 의미합니다. 영문의 경우, 관사와 같이 의미 없는 단어들이 stopwords로
지정돼있어 따로 지정해주지 않아도 되지만 한글은 지원하지 않기 때문에 직접 입력해주
어야합니다.
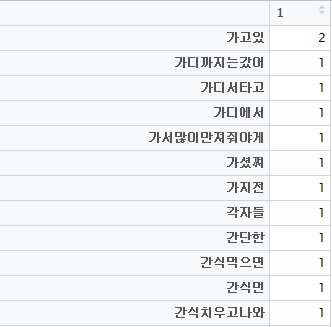
as.marix 함수를 사용해 TermDocumentMetrix를 Metirx파일로 바꿔주면 분석 결과를 볼 수 있습니다.
5. 정렬하기
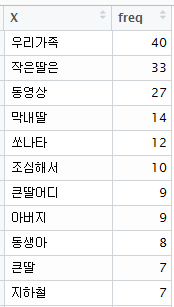
결과를 보기 쉽게 하기위해 sort 혹은 order 함수를 통해 내림차순으로 정렬합니다. 내림차순으로 결과를 정렬하면 예상치 못하게 포함된 무의미한 단어의 반복, 불필요한 정보를 제거하기에 용이합니다.

wordcloud함수는 데이터프레임 형식을 지원하기 때문에 X변수에는 name함수로 v 데이터의 이름을 추출한 값을, freq변수에는 v의 값을 입력합니다.
6. wordcloud
wordcloud2 함수를 이용해 데이터를 시각화합니다.

저희 가족은 동영상 공유를 가장 많이했고, 전반적으로 출퇴근 시간에 나누는 내용이 대화의 주를 이루고 있음을 알 수 있습니다.
'R' 카테고리의 다른 글
| R 웹 크롤링 or 워드클라우드 (0) | 2018.10.17 |
|---|---|
| R을 이용한 차트 그리기 (0) | 2018.10.16 |
| R 기본 데이터형 (0) | 2018.10.14 |
| R 기본 문법 연습 3 (0) | 2018.10.14 |
| R 기본 문법 연습 2 (0) | 2018.10.14 |